반응형
This post heavily relies on the book 'Natural Language Processing with Pytorch':
https://books.google.co.kr/books?id=AIgxEAAAQBAJ&printsec=copyright&redir_esc=y#v=onepage&q&f=false
Corpus
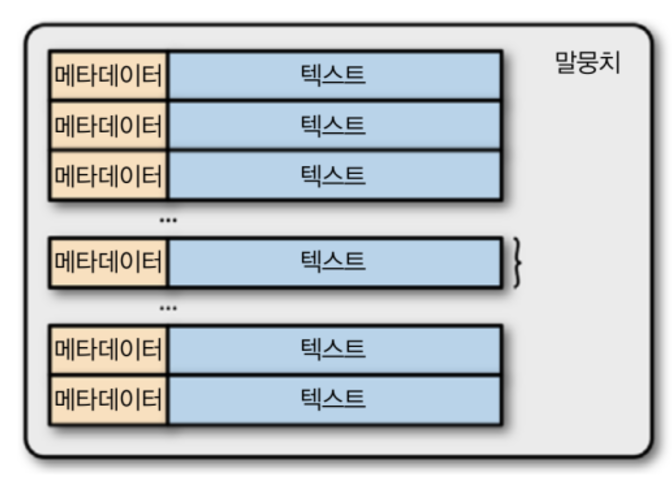
- All NLP tasks begin with text data called a corpus(corpa in plural).
- A corpus typically includes raw text (in ASCII or UTF-8 format) and metadata associated with this text.
- While raw text is a sequence of characters (bytes), it's generally more useful when characters are grouped into sequential units called tokens.
- In English, tokens correspond to words and numbers separated by spaces or punctuation marks.
- Metadata can be any supplementary information related to the text, such as identifiers, labels, timestamps, etc.
- In the field of machine learning, text with metadata is called a sample or datapoint.
- When these samples are collected together, they form what is called a corpus or dataset.
Token
- Tokenization refers to the process of dividing text into tokens.
- Tokenization can be more complex than simply splitting text based on non-alphabetic and non-numeric characters.
- For example, in agglutinative languages(교착어) like Turkish, splitting by spaces and punctuation marks is not sufficient.
- Agglutinative languages are languages where roots(어근) and affixes(접사) determine the function of words.
- Korean is also an agglutinative language.
- The tokenization problem can be completely avoided by representing text as a byte stream in neural networks.
- In fact, there are no exact standards for the tokenization process.
- In other words, the criteria for tokenization varies depending on the approach.
- However, these decisions can have a bigger impact on actual accuracy than one might think.
- Most open-source NLP packages provide basic tokenization to reduce the burden of tedious preprocessing work.
- There are packages like NLTK and spaCy.

Type
- Types are unique tokens that appear in a corpus.
- The collection of all types in a corpus is called a vocabulary(어휘 사전) or lexicon(어휘).
- Words are divided into content words(내용어) and stopwords(불용어).
- Stopwords, such as articles(관사) and prepositions(전치사), are mostly used for grammatical purposes to support content words.
N-gram
- N-grams are consecutive token sequences of fixed length (n) in text.
- Bigrams consist of two tokens, while Unigrams consist of one token.
- Packages like NLTK and spaCy provide convenient tools for creating n-grams.
- Character N-grams can be generated if subwords themselves convey useful information.
- For example, the suffix 'ol' in methanol indicates a type of alcohol.
- In tasks involving the classification of organic compound(유기화합물) names, information from subwords found through n-grams would be useful.
- In such cases, the same code can be reused, but all character N-grams are treated as single tokens.

Lemma 표제어
- A lemma is the base form of a word.
- Variations of the verb 'fly' such as 'flow', 'flew', 'flies', 'flown', 'flowing' are different forms of the word with changed endings.
- 'Fly' is the lemma for all these word variations.
- It's often helpful to reduce the dimensionality of vector representations by converting tokens to their lemmas.
- This reduction process is called lemmatization.
- For example, spaCy uses a predefined WordNet dictionary to extract lemmas.
- However, lemmatization can be represented as a machine learning problem that attempts to understand the morphology of a language.

Stemming 어간 추출
- Stemming is a reduction technique used as an alternative to lemmatization.
- It uses manually created rules to cut off word endings and reduce them to a common form called a stem(어간).
- The Porter and Snowball stemmers implemented in open-source packages are well-known.
- For example, with the word 'geese', lemmatization would produce 'goose', while stemming would produce 'gees'.
Part-of-Speech(POS) Tagging 품사 태깅

- The concept of assigning labels to documents can be extended to words or tokens.
- An example of word classification tasks is part-of-speech tagging as above.
Chunking
- Chunks are meaningful groups of words that form a single semantic unit.
- Sometimes labels need to be assigned to text phrases that are distinguished by multiple consecutive tokens.
- The process of dividing a sentence like "Mary slapped the green witch" into noun phrases (NP) and verb phrases (VP) like [NP Mary] [VP slapped] [NP the green witch] is called chunking(청크 나누기) or shallow parsing(부분 구문 분석).

- The purpose of shallow parsing is to derive higher-level units composed of grammatical elements such as nouns, verbs, and adjectives.
- If there is no data available to train a shallow parsing model, you can approximate shallow parsing by applying regular expressions to part-of-speech tagging.
- Fortunately, for widely used languages like English, such data and pre-trained models are already available.
Named Entity Recognition 개체명 인식
- Named entities are another useful unit.
- Named entities are strings that refer to real-world concepts such as people, places, companies, and drug names.

Parsing
- Unlike shallow parsing which identifies phrase units(구 단위), parsing refers to the task of understanding the relationships between phrases.

- A parse tree shows how grammatical elements within a sentence are hierarchically related.
- The tree above is called constituent parsing(구성 구문 분석).
- Another method of showing relationships is dependency parsing(의존 구문 분석).

Sense
- Words can have more than one meaning.
- Each distinct meaning that a word represents is called a sense of the word.
- Word meanings can also be determined by context.
- The automatic identification of word senses in text was actually the first semi-supervised learning application in NLP.
Be the best version of yourself, not a mediocre copy of someone else.
- Max Holloway -
반응형
'NLP' 카테고리의 다른 글
| [LLM] 1. Prompt Engineering Basics #1 (0) | 2025.01.05 |
|---|---|
| [NLP] 3. How does Transformer Work? (1) | 2025.01.03 |
| [Prompt Engineering] 2. Zer0-shot Prompting (1) | 2025.01.02 |
| [Prompt Engineering] 1. Few-shot Prompting (0) | 2025.01.02 |
| [NLP] 1. Natural Language Processing Basics (1) | 2024.11.18 |